
KoreanFoodie's Study
[OpenGL ES] 7강 : 래스터라이저(Rasterizer), Clipping, Back-face culling 본문
[OpenGL ES] 7강 : 래스터라이저(Rasterizer), Clipping, Back-face culling
GoldGiver 2023. 4. 16. 22:51
이 강의는 유투브에 무료로 공개되어 있는 한정현 교수님의 컴퓨터 그래픽스 강좌를 정리한 글입니다. 자세한 내용은 강의를 직접 들으시거나 책을 구입하셔서 확인해 보세요. 강의 자료는 깃헙 링크에 올라와 있습니다.
요약 :
1. Rasterizer(래스터라이저) 는 5가지 처리를 수행한다 : Clipping, Perspective division, Back-face culling, Viewport transform, Scan conversion 이 그것이다.
2. 클리핑은 클립 공간에 걸친 폴리곤의 경우, 클립 공간을 벗어나는 폴리곤을 일부를 잘라내는 것을 의미한다. Perspective division 은 Clip 공간을 NDC 로 변환하며, Back-face culling 을 통해 카메라에서 보이지 않는 폴리곤을 걷어내고, Viewport transform 으로 NDC 를 Screen space 로 변환한다. 마지막으로 Scan conversion 을 통해 삼각형 폴리곤 내부에 있는 각 픽셀들의 attributes(normal, texture coordinates 등)을 보간해 준다.
3. Rasterizer 의 처리는 하드웨어에서 처리해 주며, 일반적으로 프로그래머가 개입하는 부분은 없다. 😉
래스터라이저(Rasterizer)
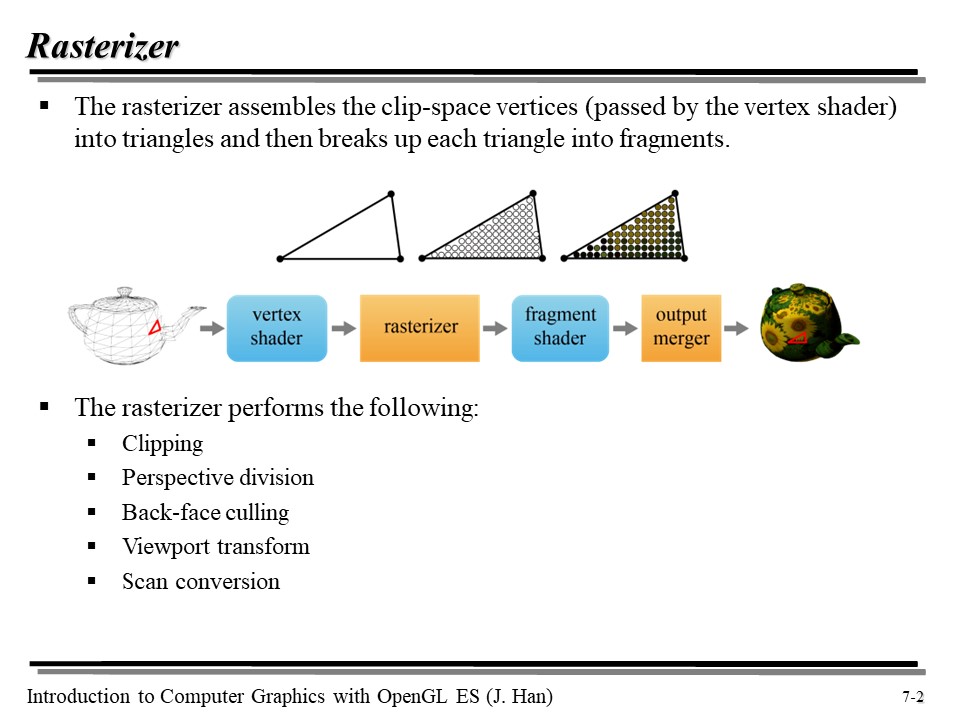
래스터라이저는 크게 다섯 가지 작업을 수행한다. 이 강에서는 이 5가지 작업 각각에 대해 자세히 알아볼 것이다.
- Clipping
- Perspective division
- Back-face culling
- Viewport transform
- Scan conversion
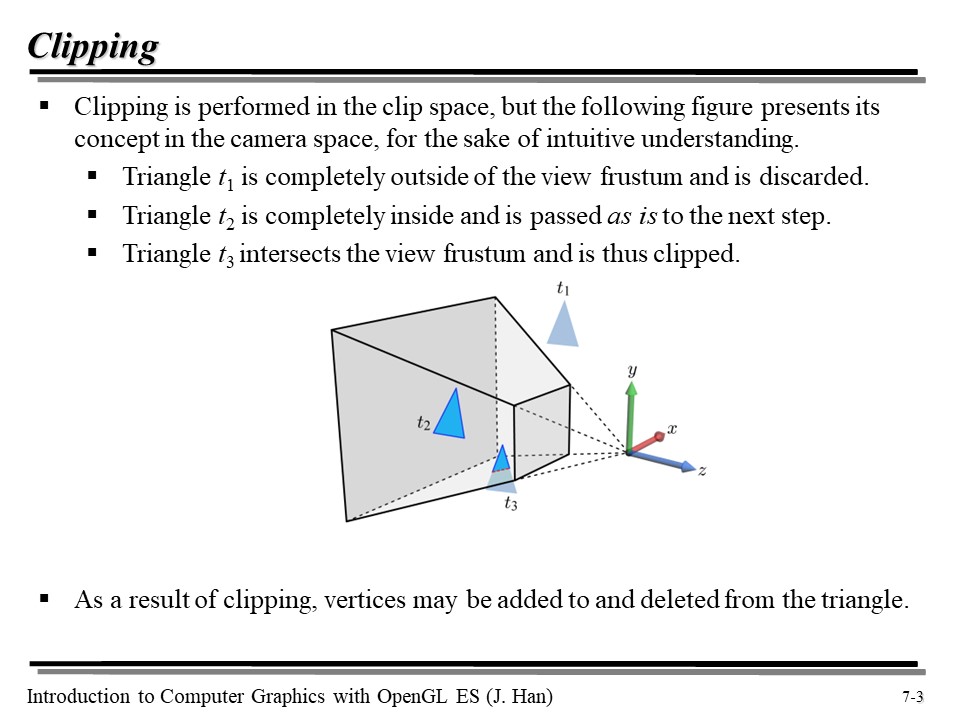
위의 그림을 보자. t1 은 그냥 간단하게 전부 제외시키고, t2 는 모두 포함시키면 되지만, t3 같은 경우는 일부만 잘라내어야 한다. 그런데 이런 작업은 하드웨어가 잘 처리해 주므로, 여기서는 그렇게 자세히 다루지는 않겠다 😅

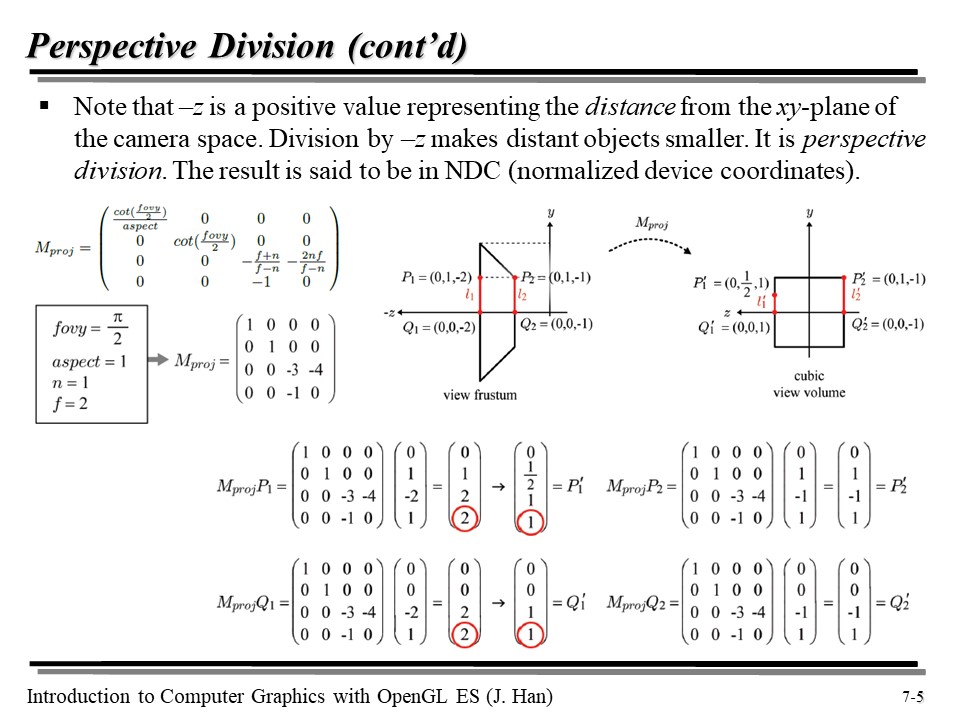
위의 M(proj) 행렬의 4번째 행을 보면 값이 -1 임을 알 수 있다. 이 값이 1 이 아니라 -1 인 이유는 무엇일까?
일단, 위의 행렬로 만들어진 동차 좌표계를 다시 카테시안 좌표계(데카르트 좌표계)로 변환하려면, 각 원소를 -z 로 나누어 주면 된다.
위에서 fovy 를 보자. 이 값은, view frustum 의 원점 (0, 0, 0) 에서 y 축의 양/음의 축을 얼만큼의 각도만큼 담아낼 것인지를 의미한다. 아래를 보면...
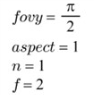
fovy 는 90도 이고 aspect 는 1 이므로, x 축으로도 양/음 축으로 90 도 만큼의 공간에 있는 오브젝트들이 담길 것이다.
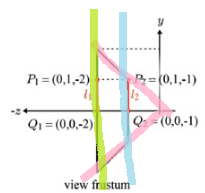
위의 그림을 보면, 분홍색 라인이 fovy 에 정해진 만큼의 각도를 표시한 것이고, n 이 1 이므로 -z 축 좌표에서 -1 이 되는 지점에 nearest plane 이 생길 것이며, farthest plane 은 f 가 2 이므로 -2 인 지점에서 정의될 것이다!
그런데 l1 과 l2 를 보자. 해당 행렬에 Projection Matrix 인 M(proj) 를 곱하면 결과가 다음과 같은데...
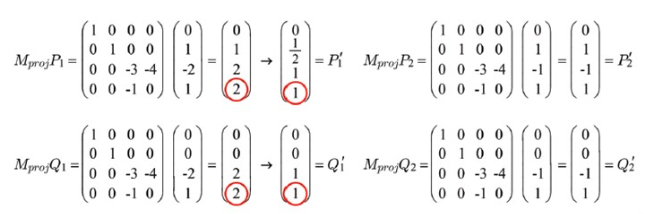
위의 변환된 좌표들을 그려보면 다음과 같다 :
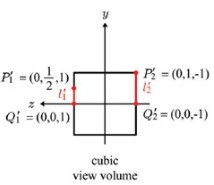
View Frustum 에서는 l1 과 l2 의 길이가 같았지만, Clipping Space 로 넘어오면서 l1' 과 l2' 의 길이가 달라졌음을 알 수 있다. 이런 식으로 변화된 이유는... P1 과 Q1 의 행렬에서 빨간색 동그라미 친 부분에서 보이듯, w 값으로 행렬의 각 요소값을 나누어 주었기 때문이다(동차좌표계에서 데카르트 좌표계로의 변환). 해당 절두체를 (-1, 1) 의 x 좌표값을 가지는 클립 공간으로 변환하는 과정에서 이런 일이 발생한 것이다.
그렇다면 l1' 과 l2' 의 길이가 다르다는 것은 어떤 의미를 가질까? 이것이 바로 원근법 구현의 간단한 원리이다!
P1 과 Q1 은 w 의 값이 -2 인데, 만약 원점으로부터 P1, Q1 에 비해 더 멀리 떨어진(예를 들어 w 값이 -3인 점 두개가 이루는 선분이 있다고 하자) 점 두개가 있다면... 해당 두 점이 이루는 선분의 길이는 클립 공간에서는 절두체에서의 원래 길이보다 3배 짧아질 것이다!
-z 로 각 원소를 나누는 이 과정을 perspective disvision 이라고 부르며, 그 결과는 NDC(Normalized Device Coordinates)에 있다고 부른다.
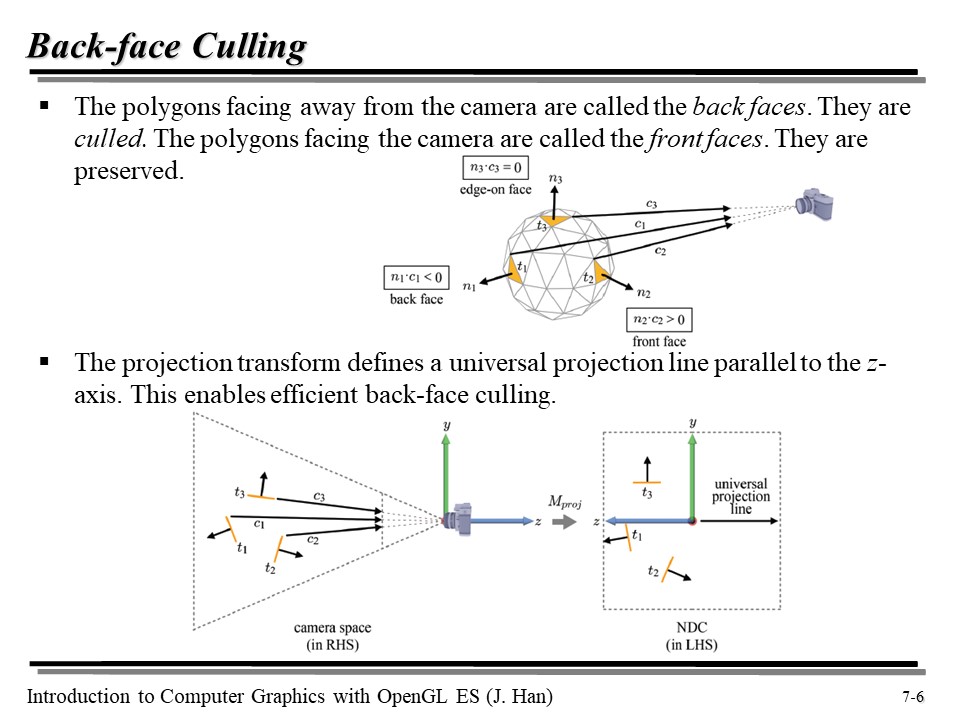
위의 그림에서 카메라가 구를 그려낸다고 해 보자. 위에서 t1 삼각형의 경우, 카메라와 반대되는 방향의 normal vector 를 갖고 있는데, 이러한 폴리곤을 back face 라고 부른다. back face 인 폴리곤은 렌더링되지 않을 것이다(컬링). 반면 카메라를 바라보고 있는 폴리곤을 front face 라고 한다. 그렇다면 어떤 폴리곤이 back face 인지 front face 인지 어떻게 구분할까?
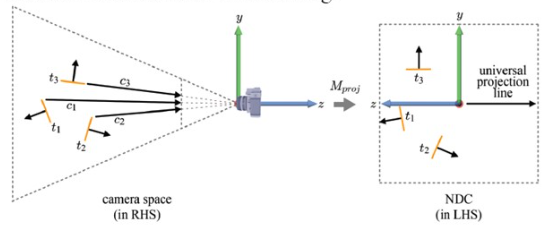
우리는 내적을 이용해 face 들을 구분한다. t3 의 경우, c3 벡터와 수직이므로 내적값이 0 이다. 이 경우를 edge-on face 라고 한다. 반면, 내적값이 양수이면 front face, 음수면 back face 가 된다.
그런데 camera space 를 clip space 로 변환하면 카메라가 각 물체까지 뻗어나가는 벡터가 모두 같게 된다(이전에는 c1, c2, c3 로 각각 달랐지만). 이를 universal projection line 이라고 하고, 해당 변환에 따라 t1, t2, t3 또한 normal 이 조금 달라진다. 즉, camera space 에서 내적을 취해 c1, c2 ,c3 를 각각 따로 쓰는 것보다, NDC 공간에서 universal projection line 한 개를 재활용하는 것이 더 효율적일 것이다.

아래 사진처럼, xyz 축의 원점에 눈이 있다고 가정해 보자.
그럼 t2 삼각형을 관찰했을 때는 가운데 삼각형 모양처럼 v1 이 오른쪽에 위치해 있을 것이다. 그러므로, v1, v2, v3 로의 방향은 반시계가될 것이다.
그런데 t1 의 경우, 사정이 조금 다르다. 마치 우리는 구 안에서 삼각형 t1 을 관찰한 것처럼 될 것이므로, t1 삼각형의 경우 v1 이 왼쪽에 위치하게 된다.
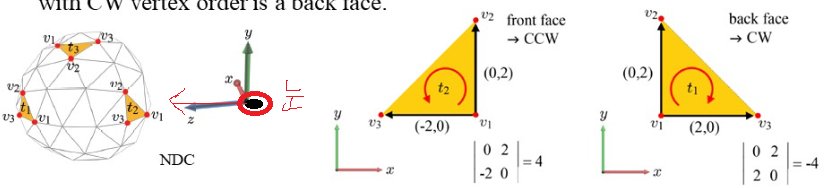
위 경우, t2 삼각형에서 벡터 v1->v2 와 v1->v3 의 외적을 취하면(즉, 넓이를 구하면) 양수가 되고, t1 삼각형의 경우 음수의 값이 나온다. 즉, 우리는 front face 의 넓이(외적)은 양수, back face 는 음수가 나온다는 것을 알 수 있다. 아래가 해당 식을 보여준다.
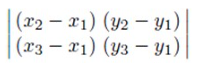
양수가 나온다는 것은 CCW(반시계 방향), 음수가 나온다는 것은 CW(시계 방향) 으로 vertex 방향이 정의되었다는 것도 기억해 두자. 행렬식이 0 이면 해당 폴리곤은 edge-on face 라는 뜻이다.

그런데 만약 반투명한 구를 렌더링해야 한다면, back face 라고 해서 무조건 culling 을 시키면 안된다. 왜냐하면 back face 의 일부를 사용자에게 보여 주어야 하기 때문이다.
따라서 OpenGL 에서도 이를 조절할 수 있다. glEnable 의 경우, 컬링을 할 것인지 설정하는 데 사용되고, glCullFace 시 어떤 face 를 culling 시킬지 인자를 세팅할 수 있다. 물론 기본값은 back face 이다.
glFrontFace 는 front face 의 vertex order 를 선택할 수 있게 해 준다. 기본값은 우리가 배웠듯이 반시계(GL_CCW)이다.
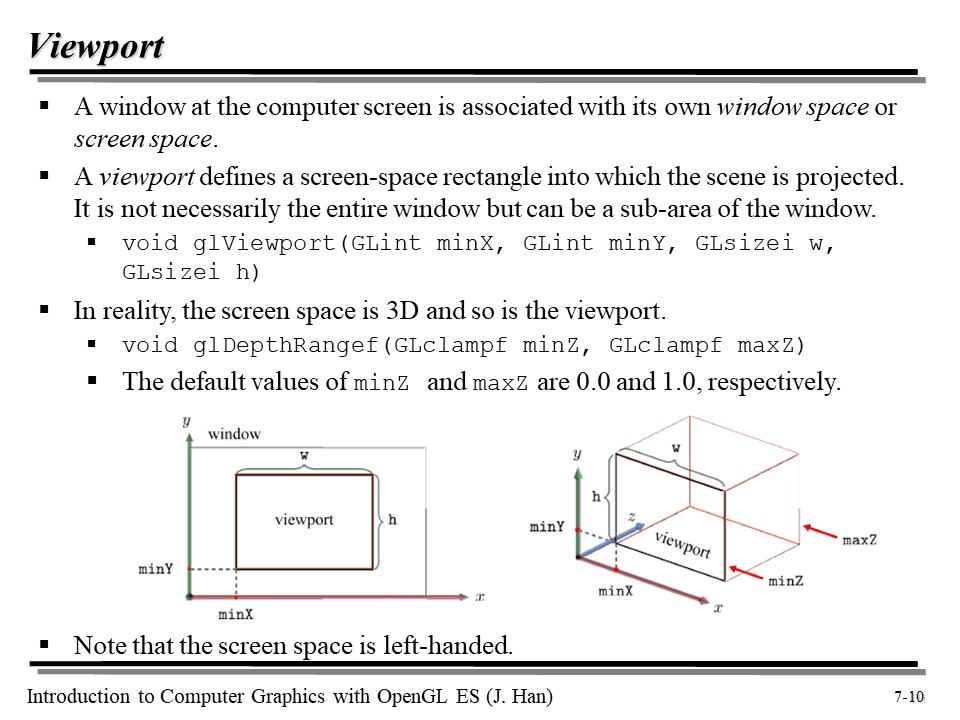
컴퓨터 스크린에서, 윈도우는 window space 나 screen space 로 구성된다.
Viewport 는 씬이 투영되는 스크린에서의 공간을 정의한다. 여기에는 minX, minY, w, h 값이 필요한데, 각각의 값은 그림으로 보는 게 이해가 더 빠르다. 또한, 해당 스크린 공간은 사실 3D 이다. 즉, 깊이 값이 있다는 뜻이다!
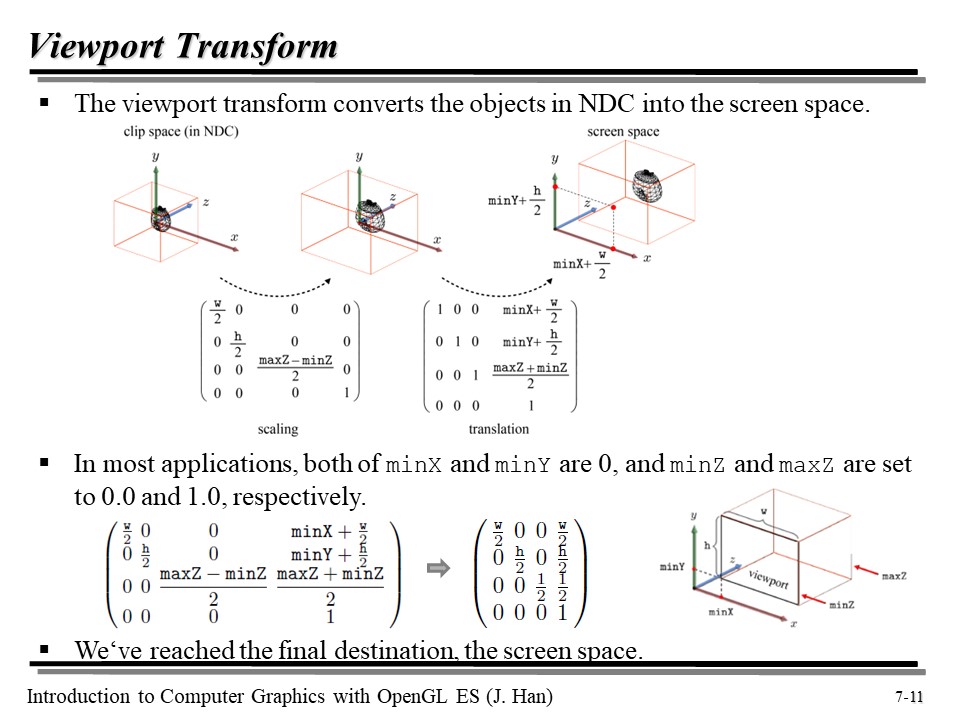
NDC 는 이전에 2 x 2 x 2 사이즈의 공간(정육면체)라고 배웠다. 빨간 색으로 강조한 것은 실수가 아니다.
위 그림은 NDC(Clip space) 에서 screen space 로의 변환을 보여주고 있다. scaling 과 translation 에 해당하는 행렬이 왜 저런 값을 가지는지는... 그냥 논리적으로 생각하면 된다. 그냥.. scaling 으로 공간의 크기를 바꾸고, minX, minY 에 해당하는 점을 맞춰준 것 뿐이다.

우리가 이전에 배웠던 vertex shader 의 OpenGL 에서의 구현을 다시 살펴 보자. 우리는 이전에 vertex shader 가 clip space 를 Rasterizer 에게 넘겨 준다고 배운 바 있다.
Rasterizer 는 이 clip space 를 Perspective Division 을 통해 NDC 로 변환하고, 이를 다시 Viewport Transform 을 이용해 Screen space 로 변환한다.
그런데 v_normal 과 v_texCoord 를 보자. Rasterizer 는 아직 해당 두 정보를 건드리지 않았는데... Rasterizer 는 이 두 녀석을 어떻게 처리할까?
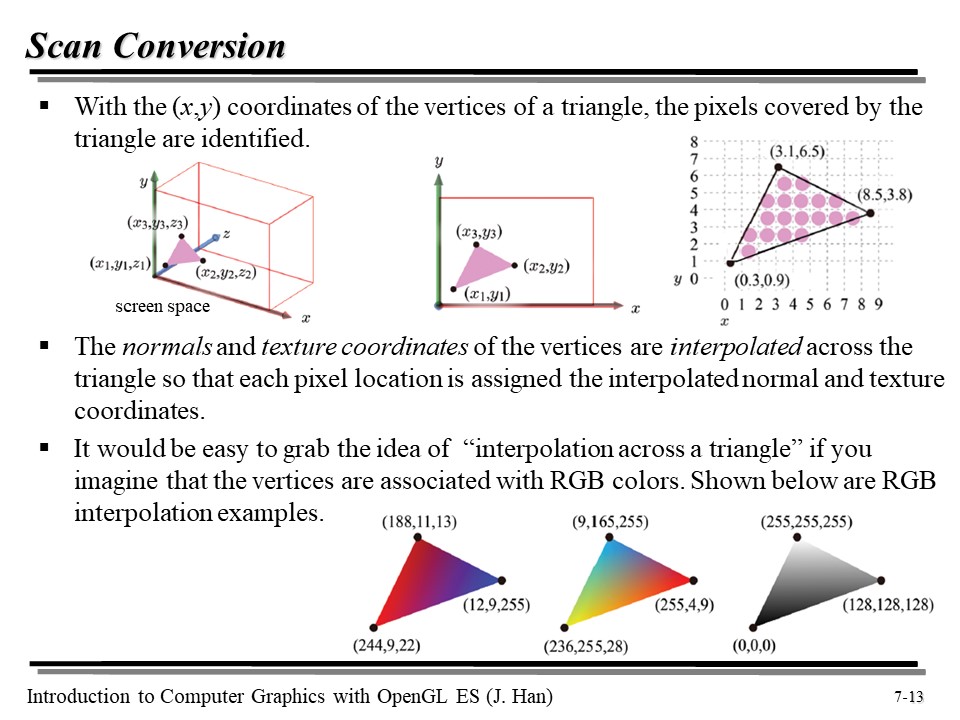
Scan Conversion 은 각각의 삼각형을 frament 의 셋으로 분해한다. 이 과정을 통해 삼각형 안에 어떤 픽셀들 포함되는지가 결정되며, 각 픽셀의 normal 과 texture coordinates 가 보간(interpolate)되어 계산되게 된다. 어렵게 표현했지만 보간이라는 건 뭐.. 그냥 평균값을 내서 대충 적절한 값을 넣어줬다고 봐도 좋다 😅
위의 삼각형에서 색상값들이 각 위치에 따라 어떻게 표현되는지를 보면 "interpolation across a triangle" 이 어떤 의미인지 확 와닿을 것이다 😆

즉, 좌표 뿐만 아니라 RGB 색상같은 attributes 들도 쉽게 보간이 된다. 이는 고등학교... 아니 중학교 수준의, 선분의 내분 같은 개념이니 간단히 넘어가겠다.
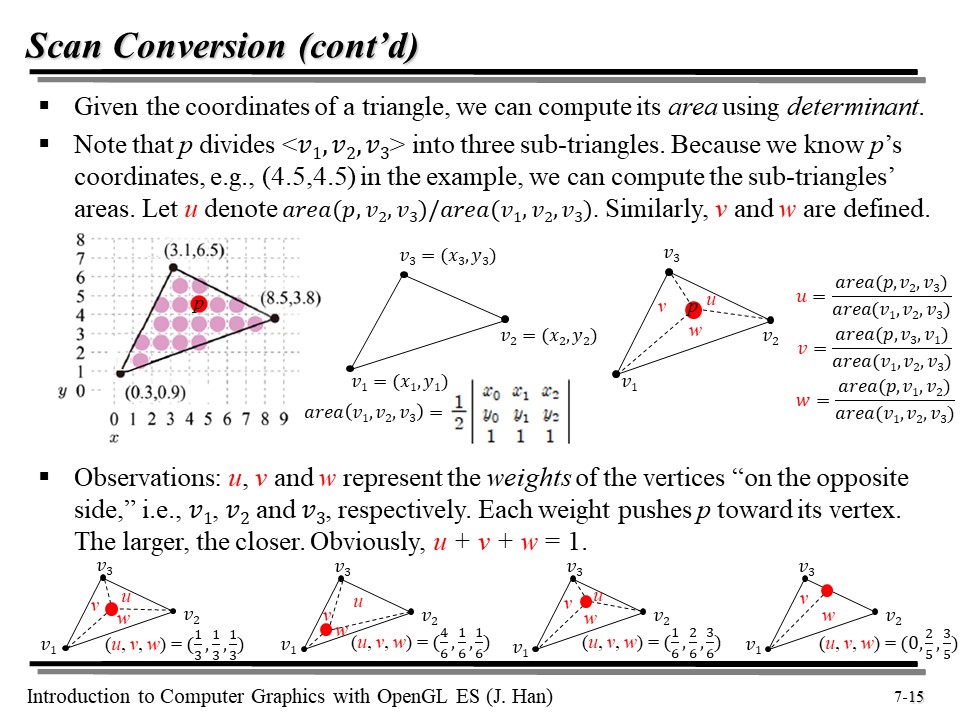
위의 그림을 잠깐 보자. p 를 삼각형 내부의 임의의 한 점이라고 가정하고, u, v, w 를 각 꼭짓점 v1, v2, v3 (반대되는 면) 에 얼마나 치우처져 있는지를 의미하는 무게(weight) 값이라고 가정하자. 그럼 삼각형을 아래와 같이 표현해 볼 수 있다.
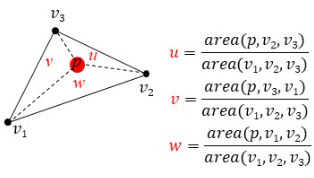
또한 u, v, w 는 원본 삼각형에서 각각 부분 삼각형의 넓이의 '비' 이므로, 합은 1 이 될 것이다.
한가지 신기한 성질은, 우리는 v1, v2, v3 좌표의 값을 알고 있으므로 u, v, w 값을 조절해 임의의 점 p 를 찍을 수 있고, 해당 점 p 의 값과 나머지 두 꼭짓점을 외적함으로써 각 부분 삼각형들의 넓이를 구할 수 있다는 것이다.

(u, v, w) 로 만들어지는 p 의 좌표계는 v1, v2, v3 에 대해 barycentric coordinates 를 갖는다고 부른다. 좌표계라고 해서 거창한 것은 아니고, p 의 x, y, z 좌표계가 v1, v2, v3 꼭짓점의 값과 u, v, w 를 이용한 식으로 표현된다고만 이해하면 된다.
어쨌듯, 우리는 barycentric coordinates 를 이용해 임의의 점 p 에 대한 보간값(그것이 좌표이든 RGB 색상 같은 다른 정보이든 간에)을 세 꼭짓점에 대해 계산할 수 있게 되었다!
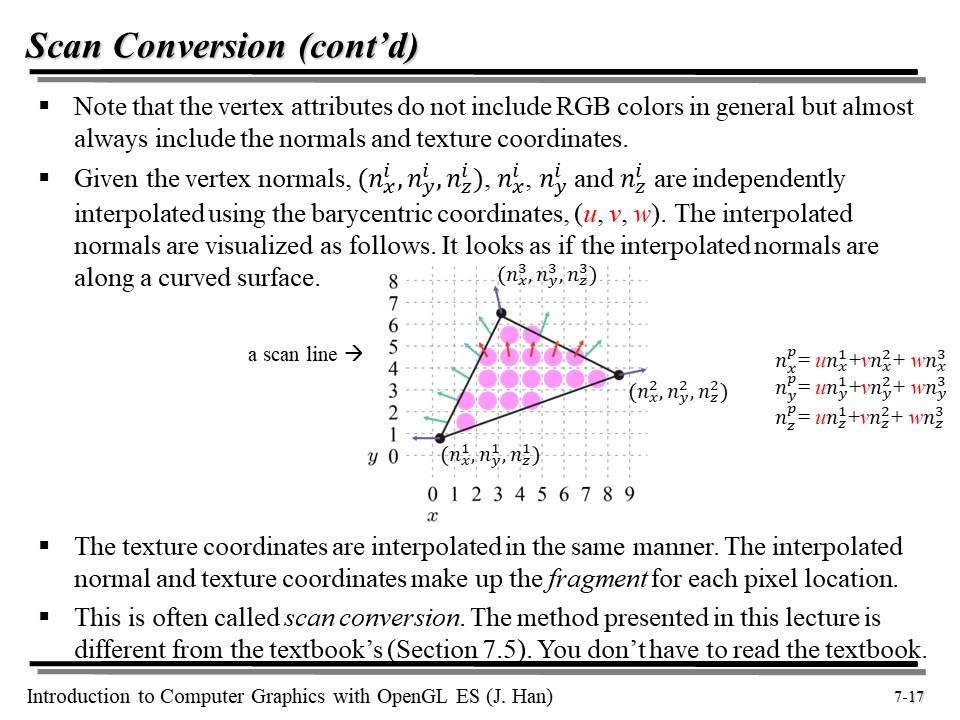
vertex attributes 는 RGB 색상을 포함하지 않는다. 그런데 대부분의 경우, normal 과 texture coordinates 값을 갖고 있다.
즉, 우리는 위에서 좌표와 RGB 색상에 보간 식을 들이댔던 것처럼, normal 과 texture coordinates 를 같은 방식으로 보간시키면 된다. 해당 계산식은 아래와 같다.
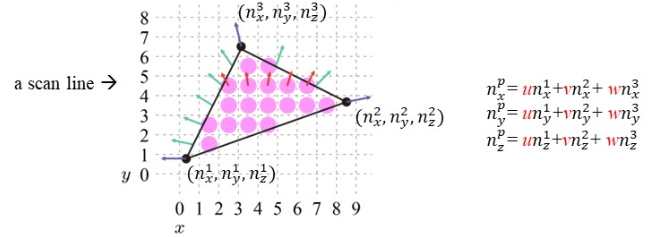
다만 우리가 기억해야 할 것은, 각각의 픽셀은 일정한 간격에 찍힌 녀석이므로, 일정 간격에 맞게 보간이 된다는 것만 기억하자. scan line 을 각각의 점선... 정도로 이해하고, 해당 점선들을 따라서 각 픽셀에서의 보간이 이루어진다고 생각하면 된다.



